Larger → more predictable
Let's begin with a terse statement of the law of large numbers (sometimes called Bernoulli's law), then pick it apart to see what it means:
In repeated independent tests with the same probability, p, of some outcome in each test, the chance that the fraction of times that the outcome occurs differs from p converges to zero as the number of trials approaches infinity.
The law of large numbers (LLN) says that if we're interested in some probability experiment, say the rolling of a single six-sided die, the probability of rolling, say, a 3, is known (P(3) = 1/6), and is the same for each roll of the die. In other words, the trials are independent. While it's entirely possible to roll five 3's in a row, which might make us think that P(3) is large, it's much less likely that if we roll the die 1000 times, we'll get all 3's. We'd in fact expect 3 to come up about 1/6 of the time.
Here's an example of how it works: If we calculate the average of all six sides of a die (half a pair of dice), we get (1 + 2 + 3 + 4 + 5 + 6) / 6 = 3.5.
Now of course we won't ever roll a 3.5, so getting that average on a single roll is impossible. It's also unlikely after just a handful of rolls.
For example, if we rolled two 6's and a 5, our early average would be about 5.67. But over a large number of rolls, as the graph on the right shows, the average of all rolls will get closer and closer to our "expected average" of 3.5.
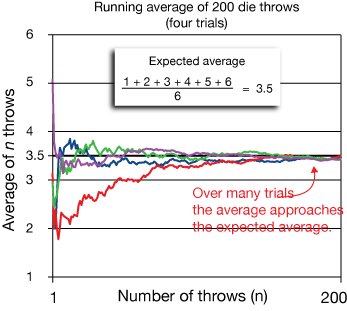
Law of large numbers
Given enough trials, the average value of any random event will approach its calculated average. We can think of it this way: Things that are essentially random by nature can become quite predictable if we observe them for long enough.
Live example: Rolling a die
Here's a little illustration of the law of large numbers using tosses of a six-sided die. The average of the six posible outcomes, {1, 2, 3, 4, 5, 6}, is 3.5, not a value we could actually roll, but it is the exact average of that uniform probability distribution (all probabilities the same) or set of possible outcomes.
Now in the first ten rolls, we could roll all ones for an average of 1 — it's possible. But we wouldn't expect any such trend to continue. Over the long run, we'd expect the average to get closer and closer to 3.5. This simulation generates a random integer between 1 and 6, simulating that die roll, and accumulates the running average of the numbers that come up on top. Notice that it does indeed fluctuate a little wildly at first, but then settles in to a value of 3.5 over many tosses of the die.
You can choose 50, 100, 500 or 1000 rolls by clicking the buttons. Do each several times to get the idea.
A proof of the law of large numbers*
Make sure to skip this proof if you've had no exposure to calculus. You can work with its results just fine.
First, recall that the mean of a set of random variables, $\{ x_1, x_2, \dots , x_n \},$ is
$$\bar{x} = \frac{x_1 + x_2 + \dots + x_n}{n}$$
The law of large numbers states that this average, $\bar{x},$ converges to its expected value, call it $\mu$, as the number of samples, $n$ goes to infinity. That is,
$$\bar{x}_n \rightarrow \, \mu \phantom{00} \text{as} \phantom{00} n \rightarrow \infty$$
Another way of stating this is that for any positive number ε,
$$\lim_{n \to \infty} \, P\left( |\bar{x}_n - \mu| \lt \epsilon \right) = 1.$$
In order to prove this limit, we have to first denonstrate what is called Chebyshev's inequality. To begin, let $X$ be a random variable and let $a$ be a positive real number, or $a \in \mathbb{R}^+$. We also assume that the $X$'s are distributed according to some distribution or probability density function, $f(x)$. Then we'll calculate the average value of $X^2$, or its expectation value, $E(X^2)$. We choose $X^2$ rather than $X$ so we don't have to worry about negative values of $X$ essentially "cancelling" our sum (integral in this case) to zero. Here's the setup:
$$ \begin{align} E(X^2) &= \int_{\mathbb{R}} x^2 f(x) dx \tag{1} \\[5pt] &\ge \int_{|x| \ge a} x^2 f(x) dx \tag{2} \\[5pt] &\ge a^2 \int_{|x| \ge a} f(x) dx \tag{3} \\[5pt] &= a^2 P(|X| \ge a) \tag{4} \end{align}$$
We can rewrite that as an inequality:
$$P(|X| \ge a) \le \frac{1}{a^2} E(X^2)$$
We can generalize this equation to any power of $X$ (which we call "moments" of the distribution) like this:
$$ \begin{align} E(|X|^p) &= \int_{\mathbb{R}} |x|^p f(x) dx \\[5pt] &\ge \int_{|x| \ge a} |x|^p f(x) dx \\[5pt] &\ge a^p \int_{|x| \ge a} f(x) dx \end{align}$$
or
$$P(|X| \ge a) \le \frac{1}{a^p} E(|X|^p)$$
for any $p = 1, 2, \dots$
Now let's use Chebyshev's inequality to prove the law of large numbers (actually what is called the weak law of large numbers. First, let $X_1, X_2, \dots , X_n$ be a sequence of independent random variables with the same distribution function. Let's let $\mu$ be the average of those numbers, $\mu = E(X_j)$, and $\sigma^2$ is the variance, $\sigma^2 = \text{Var} (X_j)$.
Now the sum of $n$ $X$ values is
$$S_n = X_1 + X_2 + \dots + X_n$$
Now define a new sum,
$$S_n^* = \frac{S_n}{n} - \mu$$
Applying Chebyshev's inequality to $S_n^*$ gives
$$E(S_n^*) = 0 \; \text{ and } \; \text{Var}(S_n^*) = \frac{\sigma^2}{n}.$$
So we have
$$P(|S_n^*| \ge \epsilon) \le \frac{1}{\epsilon^2} \text{Var}(S_n^*)$$
We can expand that last inequality like this:
$$P \bigg( \bigg| \frac{X_1 + X_2 + \dots + X_n}{n} - \mu \bigg| \ge \epsilon \bigg) \le \frac{1}{\epsilon^2} \frac{\sigma^2}{n}$$
So for every &\epsilon \gt 0$, we have, as $n \rightarrow \infty$,
$$P \bigg( \bigg| \frac{X_1 + X_2 + \dots + X_n}{n} - \mu \bigg| \ge \epsilon \bigg) \rightarrow 0,$$
which is to say that the mean of our distribution will always approach the theoretical mean ($\mu$) if we do enough iterations.
* This is not a full proof, just a hint of it. There are more sophisticated ways of looking at the law that I can provide here.
Example 1 — Diffusion
Imagine putting a drop of ink in a beaker of clear water. You've probably seen this before. The ink slowly spreads out until it uniformly colors the liquid.
The ink spreads because of random collisions between and among ink and water molecules.The cartoon below might help explain the idea.
On the top-left are two boxes separated by a barrier (thick black line). The barrier separates small red atoms (maybe those can be ink) from large blue ones.
When the barrier is removed, the random motions of the particles (atoms are always in motion) cause them to mix, eventually coming to a state (panel 4) of being completely mixed. But with such small numbers, it's possible for fluctuations to occur that would cause small imbalances (more red on one side than another, for example) to occur. For example, for small numbers, panel 4 could conceivably– and momentarily–turn back into panel 3.
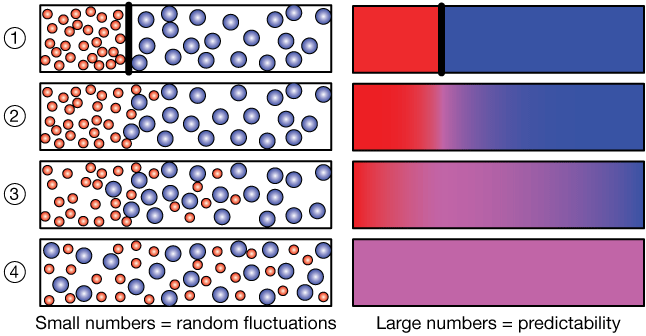
On the other hand, if we have a very large number of atoms – moles, let's say, then we observe a smooth diffusion of each side into
the other, and we never see any fluctuations that would "unmix" the atoms; the sample is just too big for that to happen.
Example 2 — Insurance
Insurance companies rely in having large numbers of people in their "pools" to even out risk and make their business predictable—something that's good for everybody.
Imagine you have an insurance company. You charge money to provide a benefit to your clients if they are involved in a certain kind of accident. Let's say that it's well known that the probability of having this kind of accident is one in 10,000 people per year.
If you have only a few clients, it's entirely conceivable that two might have an accident in same year, and that would ruin your company. But if you have 10,000 clients, then on average you'll be paying one benefit per year (some years more, some less, of course), which could conceivably be covered by the money you take in.
Large numbers of clients ensure that the risk is as close to the known odds as possible. It's a very important concept to understand for both insurers and people who make public policy about insurance.
Example 3 — Political and other polling
We see political polls and take surveys of all kinds all of the time. While most surveys have big reliability issues, polling by random sampling can be pretty reliable because of the law of large numbers.
It turns out that a sample of only 1000 people, as long as it's chosen randomly, is sufficient to predict the outcome of a presidential race to within about ±3%.
And these things have a diminishing return. By doubling the number of samples from 1000 to 2000, we don't double our accuracy to ±1.5%.
The gain scales as the square root of the number of extra samples, so we'd only gain a factor of about 1.4 (square root of 2), not 2. And adding more samples would cost more, as well.
The law of large numbers says that if we have enough samples, the average we get will converge to the "actual" underlying value.
Of course, we see polls change and have different outcomes all the time, but remember that those usually change over time as the attitudes of the voters change, and not all polls ask the same questions.
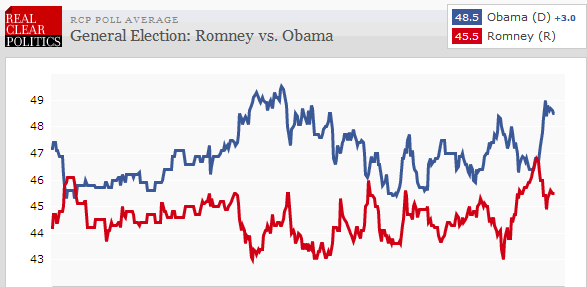
This graph shows polling data taken between Oct. 2011 and Sept. 2012, just before the presidential election between President Barack Obama and Mitt Romney. Notice that while Obama led most of the way, the difference between the two was mostly within the margin of polling error. The race turned out roughly as the polls predicted it would. Mr. Obama won 51.1% of the popular vote to Mr. Romney's 47.2%. (Source: Real Clear Politics).
Pro tip: Beware the gambers' fallacy
The law of large numbers suggests that as the number of observations grow, any random event will behave more-or-less predictably. But that does not mean that any one random event becomes more predictable. It absolutely does not. A common fallacy of gamblers is that, for example, if a six hasn't been rolled for some time on a single die, then one is "due," and we ought to bet on that. In fact, the probability of rolling a six on a fair die is 1 in 6, just as it always was.
One of the most famous examples of the gambler's fallacy occurred in a game of roulette at the Casino de Monte-Carlo in 1913. The roulette ball landed on black (about half of the slots are black, half red) 26 times in a row, an extremely unlikely occurrence. Gamblers in the casino heard about the streak and lost millions of francs betting against black. They reasoned (incorrectly) that because of the streak, red was "due" to be next. In fact, the probability of red or black for each spin of the wheel is about ½.
Terse
To be terse, or to speak or write tersely is to use few words, to be sparing with words, even to the point of abruptness. Mathematical definitions and other descriptions are often viewed as terse, but the point is to be precise and economical with words.

![]()
xaktly.com by Dr. Jeff Cruzan is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License. © 2016-2025, Jeff Cruzan. All text and images on this website not specifically attributed to another source were created by me and I reserve all rights as to their use. Any opinions expressed on this website are entirely mine, and do not necessarily reflect the views of any of my employers. Please feel free to send any questions or comments to jeff.cruzan@verizon.net.