What is a gene?
Just what a gene is is still evolving (so to speak). On the most basic level, a gene is a long sequence of the four DNA bases (A, T, G, C) that encodes a protein, which in turn can range in length from a hundred amino acids to thousands.
Relatively few genes, however, code for a protein continuously from end-to-end. Many are interrupted by stretches of DNA that don't appear to encode anything. These introns are sometimes referred to as "junk" DNA. They are stretches that sometimes have no open reading frames (ORFs), regions not interrupted by more-or-less random STOP codons. Some of these stretches are thought to have been inserted into the human genome long ago by viruses that were capable of inserting DNA into the genomes of their hosts.
Lately, however, some of that non-coding DNA has been shown to be a key factor in regulating which genes are translated into protein or RNA, and precisely when that occurs.
The field of epigenetics has emerged to study and explain features of the genome and how
and when it is transcribed and translated into RNA and protein based on factors not directly in the DNA sequence. These include that "junk" DNA, the coiling of DNA for compact storage around specialized protein molecules called histones and by special chemistries performed on DNA, such as addition of a methyl group (methylation) in key locations (adenine & cytosine).
Some of the levels of organization of a long DNA molecule are illustrated below. Visible with a light microscope by eye are chromosomes (left), DNA in its most compact "supercoiled" form.
A closer look shows that much of that DNA chain is wrapped around histone molecules that produce more compact storage. Closer still and we see the double-helix DNA strands; even closer and we see the sequence of bases, read in the 5' to 3' direction, and its mirror image — the so-called "sense" and "anti-sense" strands. Finally, some of the bases (A, C) in that DNA may be modified at times to finely tune the regulation of its expression.
ORF
(Open Reading Frame)
Roughly one out of every 20 random 3-base codons in DNA is a STOP codon. Therefore if a sequence of DNA bases is random (does not encode a protein), then on average it will contain a STOP codon about every 20 codons. An ORF is a region of DNA, sometimes thousands of base pairs long, that is not random and therefore does not contain such randomly-scattered STOPs.

We say that a gene is expressed when it is transcribed into a messenger RNA (mRNA) and then translated into a protein.
Gene regulation
In order for the sequence of a gene to be converted into a working protein with a job to do, it must be first converted into and RNA "message," then that message must be "read" by a specialized enzyme called the ribosome, where it is translated into a protein sequence. Sometimes the RNA is reconfigured before reading and sometimes the protein is reconfigured somewhat before it is put into use, of before it can achieve its "active" form.
These processes will all be covered in later sections.
On a higher level, though, cells need to determine which genes to "turn on" and "turn off", and when to do it.
As an example, let's say it's nearly lunch time and you get hungry. Aware (because your brain is) that lunch is a few minutes away, your stomach and intestines will begin to manufacture digestive enzymes. They do this by accessing the appropriate gene on its chromosome, unwinding it in preparation for reading, separating the strands, reading the DNA sequence and manufacturing a corresponding RNA. That process is known as transcription. The resulting RNA is then sent to a ribosome for translation into the encoded protein, the digestive enzyme we need.
That entire process can happen in just a minute or two.
Just how a cell knows when to turn a gene on or off, and how that's accomplished is a matter of factors that are specific to each gene and general for all or most genes.
Gene regulation is still a very active and important part of molecular biology, and there's much work to be done.
Signals
It's all about signals — chemical signals. As an example of chemical signaling, consider breathing. Why do you do it? How does your body know when it's time to breathe, and why and how does that automatically adjust when you become more or less active?
It turns out the key is carbon dioxide (CO2) in the bloodstream. In humans, there's a little CO2 detector, clusters of cells called the carotid bodies, situated at the point where the carotid arteries, the main arteries from the aorta to the head, branch off. These bodies specialize in sensing CO2. When too much CO2 builds up, they send a signal to the brain stem telling us to breathe, which pulls in more oxygen (O2) and expels more CO2. CO2 is a signal.
There are many other examples of chemical signaling. One of the most important for gene regulation is the attachment of a chemical group on some molecule that lies along the chemical "pathway" of regulation. These include
- Attachment or removal of a phosphate group (—OPO3-)
- Attachment or removal of a methyl group (—CH3)
- Attachment of removal of an acetyl group (—O-C-CH3)
- An ATP → ADP or ADP → ATP conversion
The storage of protein sequence in DNA, its transcription to RNA and translation of that RNA to a protein sequence is sometimes referred to as the central dogma of biology.
Regulation pathways — one example
Gene regulation has features that are specific to each gene, and features that are pretty much common to the regulation of all genes. One thing that confounds understanding at first is the naming of proteins and other factors involved in cell biology. Unfortunately, there's no one convention, so we just have to get used to strange names.
The figure below shows roughly how several factors (proteins and other molecules) involved in the mammalian immune response, particularly the important immune process of inflammation, are regulated. We'll go through it in 8 steps.
- Something outside of the cell, perhaps a small molecule, a piece of a foreign invader like a virus or another "signal" binds to one or more receptors in the cell wall. Remember that eukaryotic cells are highly selective about what they let in.
- Binding of signal molecules to receptors triggers a change in a protein called IκB ("eye-kappa-bee") kinase (IKK), which makes it active. This enzyme's job is, when it's active, to add phosphate groups (—OPO4) to certain target molecules. The presence of those phosphates will, in turn, signal or trigger another process to begin.
- One target of IKK is IκBα ("eye-kappa-bee-alfa"), a molecule that, in the cytoplasm of the cell is bound to a pair of DNA-binding proteins called p65 and p50.
- Once IκBα has been released from p65/p50, it is degraded by the cell and its parts either re-used or discarded.
- p65/p50 enters the nucleus and can bind to specific sites on the DNA, sites near genes that encode proteins important in the inflammation process.
- Once p65/p50 binds to its site, it can recruit a host of other transcription factors, more or fewer depending on the gene, and the RNA polymerase, which will do the work of transcribing the gene into a messenger RNA (mRNA).
- The mRNA is transported to the ribosome, a large enzyme that translates the mRNA sequence into its amino acid sequence to form a protein. There may or may not be some modification once it comes off, but it's basically done.
- Finally, the presence of a new protein in the cytoplasm of our cell will lead to a change in the role or function of the cell. In this particular case, it will secrete chemical signals to other nearby cells to tell them to begin the inflammation process, a critical part of the immune response.
When IκBα is bound to p65/p50, the complex may not enter the nucleus to access the DNA. Once IκBα is phosphorylated at key sites, it releases p65/p50.
Kinase
A kinase is any enzyme that adds a phosphate (–OPO3) functional group to another protein. Phosphorylation by kinases is a major mode of chemical "signaling" in cells. Phosphorylation is often a switch or signal that something else can now take place.

The promoter
Broadly speaking, each gene includes, at its start (5'-end of DNA), a region of base pairs called a promoter region. The promoter is a very important component in regulation of gene expression.
One thing you'll find when you begin to study gene regulation and promoters is that there is little common language, double meanings of some terms, and different terms for the same phenomenon. It's because the field of gene regulation is still a puzzle under active investigation; while much is known, there is still much to be learned. Thus we haven't yet distilled all of the knowledge, as we like to do in science, into simpler language. Maybe you can help.
Different genes contain different promoter regions. There are at least 10 different classes of promoters. Each contains several short stretches of DNA base pairs, from 4-5 to 20 or 30 base pairs long, to which transcription factors, proteins that can bind to those specific sequences on DNA, bind. Binding of these factors to the DNA of the promoter is necessary in order for transcription by RNA polymerase to begin.
Here's a schematic picture of how a promoter might look when all of the necessary proteins are assembled and transcription can begin:

In the figure, the blobs labeled TF are transcription factors, proteins that recognize and bind reversibly to a specific segment of DNA. Sometimes they do it like a pair of chopsticks grabbing either the major or minor groove of the double helix (left); other times they're more like blobs, but the binding is quite sequence-specific. Transcription factors either live in the nuclei of cells, or are transported there upon receipt of a signal by the cell (as in the regulation pathway example above).
The co-activator is often a very large protein that seems to bind to parts of transcription factors and sometimes the RNA polymerase (RNA-p) protein in order to assist in fully assembling the complex of transcription factors. Once that complex is formed, the RNA-p begins to ratchet over the DNA to copy it to an RNA base-by-base.
Different combinations of transcription factors and cofactors are used by different genes, and this combinatoric approach (think of the number of possible combinations and orders of, say, a dozen different DNA-binding transcription factors can form) leads partly to the very fine control of gene expression required by higher organisms.
The field of genetic regulation is still an active area of investigation, and one you might think about for a career. It's important stuff and we still don't know all there is to know. There is much to be done!
If you are interested in learning more about gene regulation, a nice place to start is a book called "A Genetic Switch," by Mark Ptashne. The work described in that book on the regulation of the genes of a phage (a virus that infects bacteria) was some of the first, and has helped lead to our understanding of more sophisticated gene-regulation systems.
Enhancers
If all of this wasn't crazy enough, consider another transcription-factor binding region of DNA called an enhancer.
Like a promoter sequence, an enhancer is a region of DNA that binds one or more specific kinds of DNA-binding proteins, and possibly one or more cofactors that bind to one or more of them. What's different is that the enhancer can be hundreds or thousands of base pairs away from the promoter or the gene itself, either "upstream" (toward the 5' end) or "downstream" (toward the 3' end).
What we know about genes with enhancers is that when the promoter complex is assembled, some transcription can usually occur, but when the enhancer complex (sometimes called an enhanceosome) is assembled, the transcription rate is greater (it's "enhanced").
The figure shows the strange action of an enhancer on a gene. Transcription factors assemble on both the promoter and enhancer – and remember that each of these was likely the result of some separate chemical signal that the cell received, then the two find each other as a loop of DNA, sometimes many thousands of base pairs long, forms to facilitate the linkage. The binding of the enhancer complex to the promoter complex increases the rate of transcription of the gene.
In the human genome, there are many times more enhancers than there are genes, so any gene might have more than one enhancer. One theory about why this is suggest that it helps organisms survive stressful situations where one might not provide the level of gene expression needed, but more work remains to be done. Enhancers can occur within introns, too.

Some genes encode RNAs
Some genes encode non-coding RNA, or RNA that is never translated into a protein. There are many cellular uses for such RNAs, and it seems like more are found as we go along.
One key function of some RNA strands is to fold up into 3D structures like proteins and act as enzymes in certain biochemical reactions. These RNAs are called ribozymes.
Because of the small difference in structure of the ribose sugar of RNA and deoxyribose in DNA, shown here:
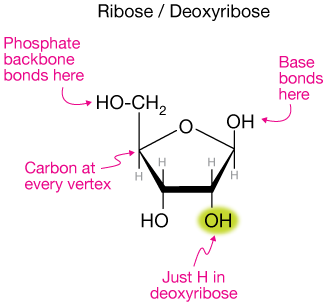
single strands of RNA can adopt many more interesting structures than DNA does. DNA is almost always found as a double helix.
Here is an example of one ribozyme, called leadzyme because it can cleave bonds in some other RNA / DNA when it binds lead ions.
Notice how the 5' – 3' chain adopts some H-bonding between bases, and in other places just forms loops. The base-pared RNA tends to be helical, while the loops can be more floppy. This kind of folding is common in non-coding RNAs.

One of the most spectacular uses of RNA in biochemistry is in the ribosome, a very large protein+RNA structure that, in turn, translates mRNA into a protein. This is a particularly nice view of much of the RNA in a ribosome. See if you can identify the RNA bits in this lovely ribbon rendering of the ribosome.

RNA World
One hypothesis about early life in Earth is that it may have been all RNA-based. It's an intriguing idea because today we see RNA used in viruses as the carrier of genetic information, in many organisms, including mammals, as a structural protein, and as an enzyme. Food for thought.
Genes as the basis of heredity
Finally, let's take a step back from the molecular nature of genes and ask what they do for individuals and their species.
Genes, sometimes individually and sometimes in coordination with other genes, encode characteristics or traits of an organism. If you have blue eyes, it's mainly because of two genes on your 15th chromosome, and in particular, just a couple of base changes in each.
We now know of single gene mutations that are responsible for diseases like breast cancer, cystic fibrosis or Huntington's disease.
The study of the passing of genes from one generation to the next is the subject of genetics, and that will be the subject of a future web page.

![]()
xaktly.com by Dr. Jeff Cruzan is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License. © 2016, Jeff Cruzan. All text and images on this website not specifically attributed to another source were created by me and I reserve all rights as to their use. Any opinions expressed on this website are entirely mine, and do not necessarily reflect the views of any of my employers. Please feel free to send any questions or comments to jeff.cruzan@verizon.net.